



A Faster PIVOT for SQL Server?
- Posted in:
- Development
- JSON
- SQL Server
- T-SQL

While working with some poorly performing code in T-SQL that used a PIVOT operator, I wondered if there was a more efficient way to get a result set of pivoted data. It may have been a fool's errand, but I still wanted to try. It dawned on me that I could use the STRING_AGG() function to build a delimited list of pivoted column names and values. From there, I'd have to "shred" the delimited data to rows and columns. But how?
SQL Server's longtime support for XML came to mind. But I quickly dismissed it--it's not my cup of tea and I've never thought of SQL Server combined with XML as a well-performing combination. What about using JSON? Could that work? And if so, would it perform well?
Below is the design pattern I settled on. There is a @Json variable that (as the name implies) holds all of the data from the result set, formatted as JSON. It gets passed to the OPENJSON() function, which returns a result set of typed columns based on what is specified in the WITH clause. The columns we *don't* want to pivot should be known at design time when the query is written--they're represented in green. The columns and data we do want to pivot may or may not be known ahead of time--they're represented in yellow. In my experience, they usually aren't known, and dynamic T-SQL must be used. I'll assume that's the case and use dynamic T-SQL for an example.
The Design Pattern
DECLARE @Json VARCHAR(MAX) = '[ { "ColName_1":"Val_1","ColName_2":"Val_2", ... "ColName_N":"Val_N", "PivColName_1":"PVal_1","PivColName_2":"PVal_2", ... "PivColName_N":"PVal_N"}, { "ColName_1":"Val_1","ColName_2":"Val_2", ... "ColName_N":"Val_N", "PivColName_1":"PVal_1","PivColName_2":"PVal_2", ... "PivColName_N":"PVal_N"}, { "ColName_1":"Val_1","ColName_2":"Val_2", ... "ColName_N":"Val_N", "PivColName_1":"PVal_1","PivColName_2":"PVal_2", ... "PivColName_N":"PVal_N"}, { "ColName_1":"Val_1","ColName_2":"Val_2", ... "ColName_N":"Val_N", "PivColName_1":"PVal_1","PivColName_2":"PVal_2", ... "PivColName_N":"PVal_N"} ]'; SELECT * FROM OPENJSON(@Json) WITH ( ColName_1 <datatype>, ColName_2 <datatype>, ... ColName_N <datatype>, PivColName_1 <datatype>, PivColName_2 <datatype>, ... PivColName_N <datatype> )
Sample Code
Here are two queries you can try for yourself with the [WideWorldImporters] database.
USE WideWorldImporters; DECLARE @SQL AS VARCHAR(MAX); DECLARE @WithCols VARCHAR(MAX); DECLARE @Json VARCHAR(MAX); ;WITH ColNames AS ( SELECT DISTINCT AccountsPersonID FROM Sales.Invoices ) SELECT --Pivoted column names that will be specified in the OPENJSON WITH clause. @WithCols = '[InvoiceID] INT ''$.InvoiceID'',' + STRING_AGG('[' + CAST(AccountsPersonID AS VARCHAR(MAX)) + '] INT ''$."' + CAST(AccountsPersonID AS VARCHAR(MAX)) + '"''', ', ') WITHIN GROUP ( ORDER BY AccountsPersonID ) FROM ColNames; SELECT @Json = '[' + STRING_AGG(CAST(t.JsonData AS VARCHAR(MAX)), ',') + ']' FROM ( SELECT N'{' + ' "InvoiceID":' + CAST(s.InvoiceID AS VARCHAR(MAX)) + COALESCE(',' + STRING_AGG('"' + CAST(s.AccountsPersonID AS VARCHAR(MAX)) + '":' + CAST(s.Quantity AS VARCHAR(MAX)), ','), '') + '}' AS JsonData --Derived table with aggregated data. FROM ( SELECT i.InvoiceID, i.AccountsPersonID, SUM(l.Quantity) AS Quantity FROM Sales.Invoices i JOIN Sales.InvoiceLines l ON l.InvoiceID = i.InvoiceID GROUP BY i.InvoiceID, AccountsPersonID ) AS s GROUP BY s.InvoiceID ) t --Parse the JSON data and return a result set. SET @SQL = ' SELECT * FROM OPENJSON(''' + @Json + ''') WITH ( ' + @WithCols + ' ) '; EXEC(@SQL); GO
USE WideWorldImporters; DECLARE @Cols VARCHAR(MAX); --Pivoted column names that will be specified in the PIVOT operator. ;WITH ColNames AS ( SELECT DISTINCT AccountsPersonID FROM Sales.Invoices ) SELECT @Cols = STRING_AGG(QUOTENAME(AccountsPersonID), ',') WITHIN GROUP (ORDER BY AccountsPersonID) FROM ColNames; DECLARE @SQL VARCHAR(MAX) = ' SELECT * FROM ( SELECT l.InvoiceID, i.AccountsPersonID, l.Quantity FROM Sales.Invoices i JOIN Sales.InvoiceLines l ON l.InvoiceID = i.InvoiceID ) p PIVOT ( SUM(Quantity) FOR AccountsPersonID IN ( ' + @Cols + ' ) ) AS pvt'; EXEC(@SQL); GO
Results and Comparison
Both query execution plans include a nonclustered columnstore index scan on [Sales].[InvoiceLines], and a nonclustered row index scan on [Sales].[Invoices]. And they each have the same number of reads. If I return the results to the SSMS grid, PIVOT takes longer--both in terms of duration and CPU.
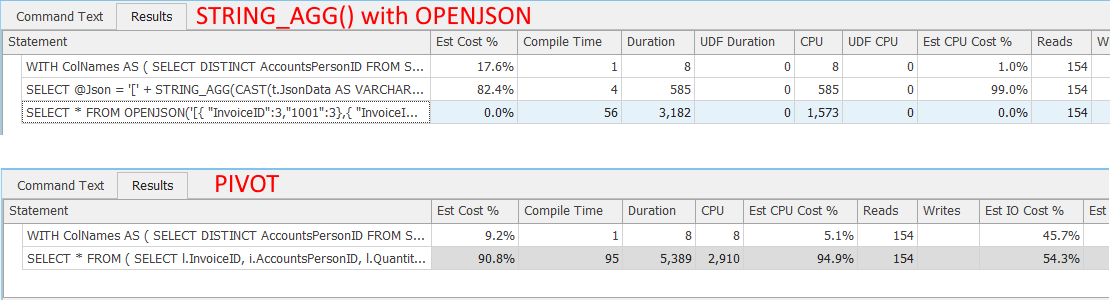
Perhaps a better comparison is to discard grid results after execution. With that setting specified in SSMS options, the execution plans remain the same. But duration and CPU are down for both plans. Here again, the plan using PIVOT takes longer.
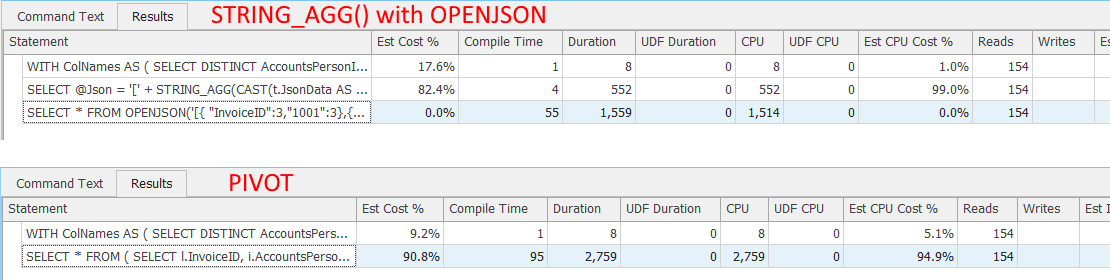
Conclusions
So did I beat PIVOT? Definitely maybe. At least for this one contrived example. I do have another example that is running in a test environment with one of my clients, and it beats PIVOT too. It has a result set of about 200 columns and 44 thousand rows. I'm not ready to declare victory, but it is intriguing. I'd like to test many, many more queries. The slight gains demonstrated here (even if consistently reproducible) are arguably not worth the hassle. I'll let you be the judge.
Comments