



Page Compression vs Compress() vs Columnstore
I recently encountered a logging table in SQL Server that was used primarily for storing JSON data. It had grown to more than 2½ billion rows and I was looking for a way to make its footprint smaller on disk, and also in memory in the event a table scan was necessary. PAGE compression was already enabled on the table, but I was hoping to squeeze the size down further. There were a couple of approaches I decided to try. The first was to use the COMPRESS() function to compress the JSON strings and store them as VARBINARY. The second was to drop the existing (rowstore) clustered index on the table and replace it with a clustered columnstore index.
For reference, here is the original table design:
CREATE TABLE dbo.LoggingTable( Id NUMERIC(12, 0) IDENTITY NOT NULL CONSTRAINT PK_LoggingTable PRIMARY KEY, FkId NUMERIC(12, 0) NULL, Item VARCHAR(20) NULL, ToInt INT NULL, FromInt INT NULL, Other_ID NUMERIC(10, 0) NULL, ColumnOrder TINYINT NULL, ReferenceTable VARCHAR(100) NULL, Action CHAR(1) NULL, Status TINYINT NULL, JsonData VARCHAR(MAX) NULL, LastModified FLOAT NULL, ModifiedBy VARCHAR(254) NULL, Pending INT NULL ) GO
Here are the results:
| Option | Table Description | Table Size (GB) |
|---|---|---|
| 1 | PAGE Compression Only | 602.06 |
| 2 | PAGE Compression, JSON data stored as VARBINARY via COMPRESS() | 522.34 |
| 3 | Table with Clustered Columnstore Index | 125.44 |
Results and Analysis
Option 1 and option 2 weren't that far apart in size. I was expecting a more significant space savings. This may be due to the nature of the JSON data more than anything. It's a "fair" comparison, though: the only difference between the table designs is the column that holds the JSON data (NVARCHAR(MAX) vs VARBINARY(MAX)). As for the space savings, I suspect it would have been greater if the JSON data strings were larger, or had some repeating names in the name/value pairs. A couple of visualizations for the JSON data size shows the vast majority of the strings were only around 220 characters in length.
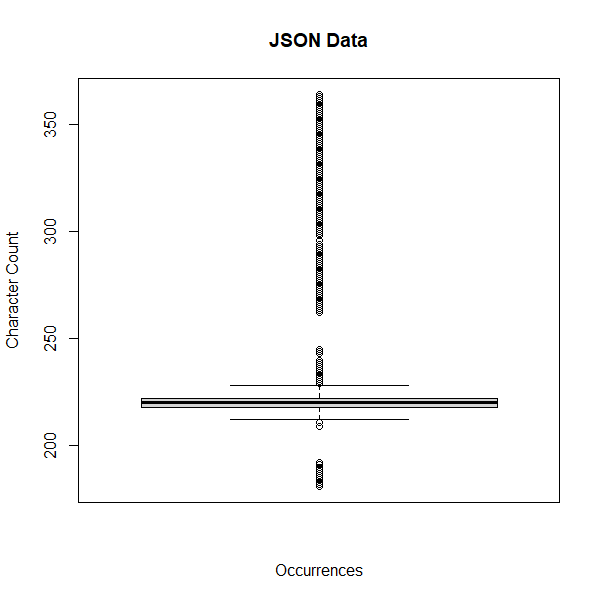
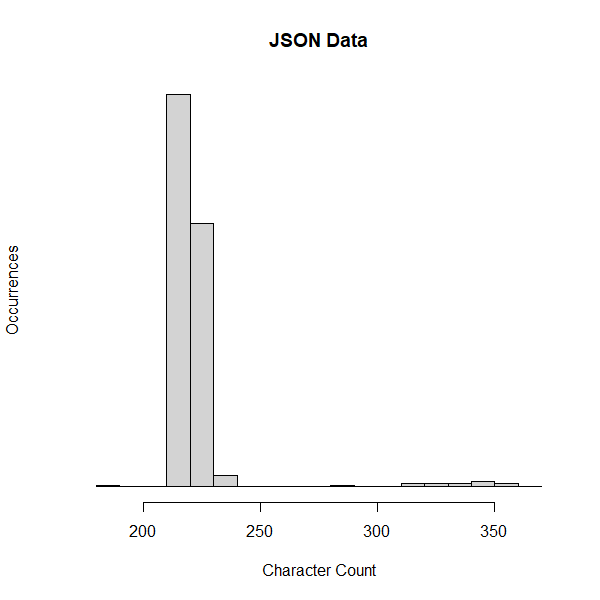
Option 3, the clustered columnstore index, was the clear winner here. But comparing option 3 to the others isn't quite fair--how much of the huge space savings is attributed to the other non-JSON data columns? I wish I'd dropped all of the columns except for [Id] and [JsonData] before performing my test. Hindsight wins again! Ultimately, option 3 and clustered columnstore indexing won out for me.
Comments