



Scraping Web Pages
- Posted in:
- Development
- Machine Learning Services
- R
- SQL Server
- T-SQL

I don't consider myself a data scientist. But that hasn't stopped me from finding some use cases for Machine Learning Services for SQL Server. One of them is acquiring data by scraping web pages. If you're a regular here, you probably know R is my language of preference. However, Python has packages for scraping web pages. I would imagine java does too.
For this post, it might make more sense to skip ahead to the end result, and then work our way backwards. Here is a web page with some data: Boston Celtics 2016-2017. It shows two HTML tables (grids) of data for the Boston Celtics, a professional basketball team. The first grid lists the roster of players. We will scrape the web page, and write the data from the "roster" grid to a SQL Server table. It will look much like this: 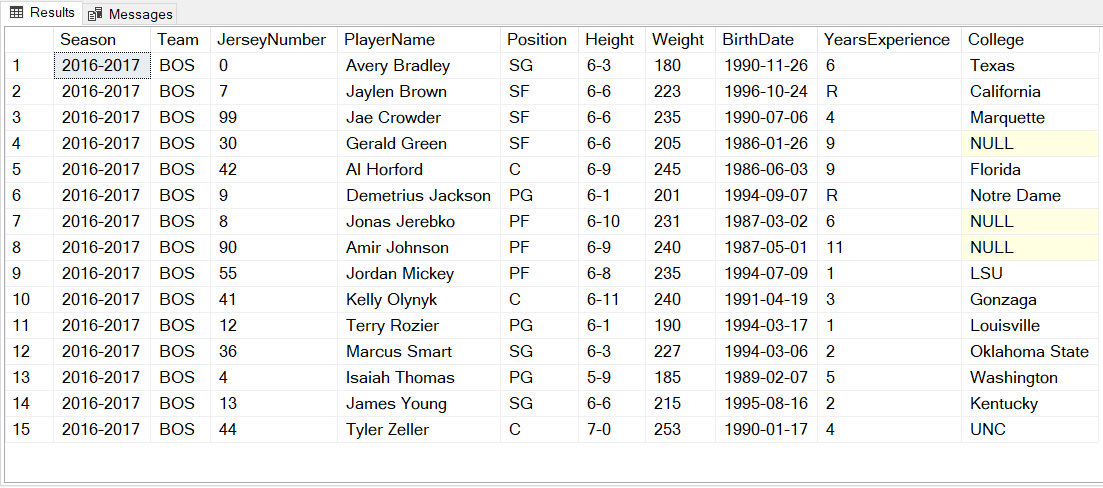
R Code
R has an abundance of packages. This frequently provides numerous options to accomplish any task. For this one, I'll be using the RCurl and XML packages. This bit of code will do most of the work in R:
library(RCurl)
library(XML)
url <- "https://DaveMason.me/p/boston-celtics-2016-2017.html"
html = RCurl::getURL(url);
tables <- XML::readHTMLTable(html, header = TRUE,
as.data.frame = TRUE,
stringsAsFactors = FALSE);
Lines 1 and 2 load the necessary R packages. Line 3 specifies the URL string for the web page we want to scrape. Line 4 gathers the entirety of HTML from the page. And Line 5 creates a list of data frames. After we run the code, we can check the length of tables to see how many HTML tables were found. In this case, there are four:
> length(tables)
[1] 4
>
Continuing on, I'll use the head() function to preview the first three rows of each data frame. This shows me the HTML table of "roster" data lies in the first data frame tables[[1]]:
> head(tables[[1]], n = 3L)
+ head(tables[[2]], n = 3L)
+ head(tables[[3]], n = 3L)
+ head(tables[[4]], n = 3L)
Jersey Number Player Position Height Weight Birthdate Years Experience College
1 0 Avery Bradley SG 6-3 180 11/26/1990 6 Texas
2 7 Jaylen Brown SF 6-6 223 10/24/1996 R California
3 99 Jae Crowder SF 6-6 235 07/06/1990 4 Marquette
Game Date Time At Opponent Result OT Points For Points Against Wins-Season Losses-Season Streak
1 1 Wed, Oct 26, 2016 7:30p Brooklyn Nets W 122 117 1 0 W 1
2 2 Thu, Oct 27, 2016 8:00p @ Chicago Bulls L 99 105 1 1 L 1
3 3 Sat, Oct 29, 2016 7:00p @ Charlotte Hornets W 104 98 2 1 W 1
CONNECT
1
NULL
>
With that, the R code that we will use in SQL Server via sp_execute_external_script will be as follows:
library(RCurl)
library(XML)
url <- "https://DaveMason.me/p/boston-celtics-2016-2017.html"
html = RCurl::getURL(url);
tables <- XML::readHTMLTable(html, header = TRUE,
as.data.frame = TRUE,
stringsAsFactors = FALSE);
OutputDataSet <- tables[[1]]
SQL Server
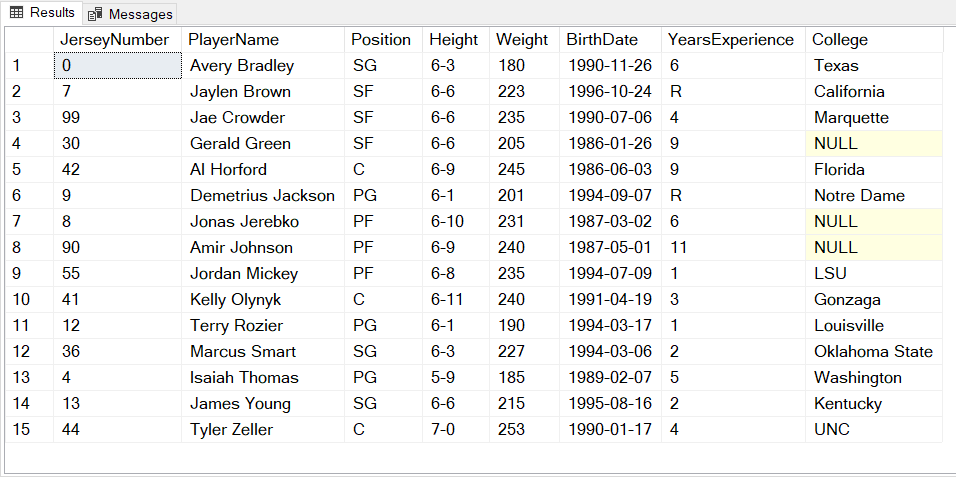
With the necessary R code in hand, let's run it in-database with Machine Learning Services. Since we know the schema, it is specified via WITH RESULT SETS:
EXEC sp_execute_external_script
@language = N'R',
@script = N'library(RCurl)
library(XML)
url <- "https://DaveMason.me/p/boston-celtics-2016-2017.html";
html = RCurl::getURL(url);
tables <- XML::readHTMLTable(html, header = TRUE, as.data.frame = TRUE, stringsAsFactors = FALSE);
OutputDataSet <- tables[[1]]'
WITH RESULT SETS (
(
JerseyNumber VARCHAR(4),
PlayerName VARCHAR(128),
Position VARCHAR(4),
Height VARCHAR(8),
Weight SMALLINT,
BirthDate DATE,
YearsExperience VARCHAR(2),
College VARCHAR(128)
)
);
If desired, we can save the output to a temp table:
USE tempdb;
GO
DROP TABLE IF EXISTS #Roster;
CREATE TABLE #Roster (
JerseyNumber VARCHAR(4),
PlayerName VARCHAR(128),
Position VARCHAR(4),
Height VARCHAR(8),
Weight SMALLINT,
BirthDate DATE,
YearsExperience VARCHAR(2),
College VARCHAR(128)
)
INSERT INTO #Roster
EXEC sp_execute_external_script
@language = N'R',
@script = N'library(RCurl)
library(XML)
url <- "https://DaveMason.me/p/boston-celtics-2016-2017.html";
html = RCurl::getURL(url);
tables <- XML::readHTMLTable(html, header = TRUE, as.data.frame = TRUE, stringsAsFactors = FALSE);
OutputDataSet <- tables[[1]]'
We can go a step further and write the data to a permanent table (it's tempdb in this example, but you get the idea). Here I'll prepend two columns to indicate the season and team:
USE tempdb;
GO
SELECT CAST('2016-2017' AS VARCHAR(9)) AS Season,
CAST('BOS' AS VARCHAR(3)) AS Team, *
INTO dbo.Roster
FROM #Roster;
Now we have the data as depicted in the first image at the top of this post:
SELECT * FROM dbo.Roster;
As it turns out, there are more web pages of Boston Celtics roster data I can scrape (note the underlying URLs, referenced in the code below):
With a couple of minor edits to the TSQL code, I can grab that data too:
--Data for 2017-2018 season.
INSERT INTO #Roster
EXEC sp_execute_external_script
@language = N'R',
@script = N'library(RCurl)
library(XML)
url <- "https://DaveMason.me/p/boston-celtics-2017-2018.html";
html = RCurl::getURL(url);
tables <- XML::readHTMLTable(html, header = TRUE, as.data.frame = TRUE, stringsAsFactors = FALSE);
OutputDataSet <- tables[[1]]';
--Data for 2018-2019 season.
INSERT INTO #Roster
EXEC sp_execute_external_script
@language = N'R',
@script = N'library(RCurl)
library(XML)
url <- "https://DaveMason.me/p/boston-celtics-2018-2019.html";
html = RCurl::getURL(url);
tables <- XML::readHTMLTable(html, header = TRUE, as.data.frame = TRUE, stringsAsFactors = FALSE);
OutputDataSet <- tables[[1]]';
Limitations of Schema
One of the drawbacks to the examples and techniques presented here is that we have to know the schema of the returned data before we can write it to a SQL Server table. If a web page has multiple HTML tables, we also have to figure out which ones have the data we intend to save. In my next post, I'll look at another option for web scraping that is not dependent on schema. In the mean time, there are a few caveats and gothcas to be aware of if you want to try web scraping in-database:
- If needed, the two packages can be installed as follows:
- install.packages("RCurl")
- install.packages("XML")
- By default, the SQL Server Setup disables outbound connections by creating firewall rules. Check out Firewall configuration for SQL Server Machine Learning Services.
- The getURL() function in the RCurl package doesn't work well (or at all) with javascript and dynamically generated HTML content. (Try scraping this page, for example.) I'm told there are other R packages that might work for those pages.
- Please take a long, hard look at The Web Scraping Best Practices Guide before you begin!
Comments