



The Bridge From NoSQL to SQL Server
- Posted in:
- Big Data
- Development
- JSON
- SQL Server
- T-SQL

Starting with SQL Server 2016, Microsoft offers support for JSON. JSON functions in SQL Server enable us to combine NoSQL and relational concepts in the same database. We can combine classic relational columns with columns that contain documents formatted as JSON text in the same table, parse and import JSON documents in relational structures, or format relational data to JSON text. Collectively, this has been referred to as a "bridge" to the NoSQL world.
Converting relational data to JSON hasn't posed many challenges. In most instances, appending a query with FOR JSON AUTO is sufficient. Here's a simple query with the JSON output:
SELECT TOP(3) *
FROM AdventureWorks.Person.ContactType
FOR JSON AUTO;
[
{
"ContactTypeID": 1,
"Name": "Accounting Manager",
"ModifiedDate": "2002-06-01T00:00:00"
},
{
"ContactTypeID": 2,
"Name": "Assistant Sales Agent",
"ModifiedDate": "2002-06-01T00:00:00"
},
{
"ContactTypeID": 3,
"Name": "Assistant Sales Representative",
"ModifiedDate": "2002-06-01T00:00:00"
}
]
Parsing JSON data to a tabular result set is more complicated. (Although JSON data is commonly hierarchical, I'll focus on tabular data in this post.) The OPENJSON function will be one of the primary functions used to parse JSON data. The schema of the result set returned by the function can be the default schema or an explicit schema. Let's parse the data from above with the default schema:
DECLARE @JsonData NVARCHAR(MAX) = '[
{
"ContactTypeID": 1,
"Name": "Accounting Manager",
"ModifiedDate": "2002-06-01T00:00:00"
},
{
"ContactTypeID": 2,
"Name": "Assistant Sales Agent",
"ModifiedDate": "2002-06-01T00:00:00"
},
{
"ContactTypeID": 3,
"Name": "Assistant Sales Representative",
"ModifiedDate": "2002-06-01T00:00:00"
}
]'
SELECT j.*
FROM OPENJSON(@JsonData) j
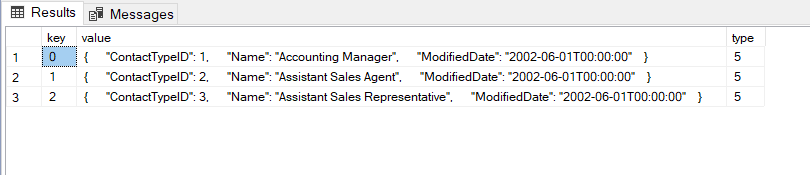
The default schema returns key/value pairs, along with a numeric "type" for the JSON value. Above, we see each "row" as a value of type 5 (JSON object type), itself comprised of key/value pairs, with the keys representing column names from the original query. Perhaps you were expecting the result set to look something like this:
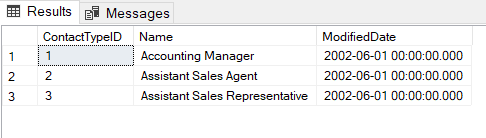
For that, we'll need an explicit schema where we specify the column names and data types (for brevity, I'll reuse the @JsonData variable and the JSON data value shown earlier):
SELECT *
FROM OPENJSON(@JsonData)
WITH (
ContactTypeID INT,
Name NVARCHAR(50),
ModifiedDate DATETIME
)
Here, the column names match the key names of the JSON data. We can also use the JSON_VALUE function to achieve the same result set:
SELECT
JSON_VALUE(j.value, '$.ContactTypeID') AS ContactTypeID,
JSON_VALUE(j.value, '$.Name') AS Name,
JSON_VALUE(j.value, '$.ModifiedDate') AS ModifiedDate
FROM OPENJSON(@JsonData) j
In both situations, we need to know something about the JSON schema to query it in a meaningful way: in the first example, column names and types are hard-coded; in the second example, column names are hard-coded as path parameter values for the JSON_VALUE function. Even though JSON data is self-describing, SQL Server doesn't have a way to infer schema. (I would be quite happy to be wrong about this--please add a comment if you know something I don't!) About the time I came to this realization, I commented on Twitter that JSON might be fool's gold. You don't need to know schema to store JSON data in SQL Server. But you do if you want to query it. "It's pay me now or pay me later."
If I could wave my magic wand, I'd make some enhancements. OPENJSON already has a default schema (no WITH clause) and an explicit schema (a WITH clause that specifies column names and types). How about an implicit or inferred schema? With this option, SQL would use the keys and types from the first "row" and those would become the column names and types of the result set. Syntax might look something like this:
SELECT *
FROM OPENJSON(@JsonData, 'lax/strict $.<path>')
WITH SCHEMA IMPLICIT;
The OPENJSON function already has options for lax vs strict. With lax mode, data that can't be cast to the inferred/implicit data type would be returned as NULL, whereas with strict mode, an error would occur.
Another enhancement idea is to allow dynamic explicit schemas. With the use of CROSS APPLY, we can get the key names and types from JSON:
SELECT k.[key], k.[type]
FROM OPENJSON(@JsonData) j
CROSS APPLY OPENJSON(j.value) k
WHERE j.[key] = 0
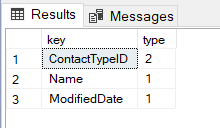
As it is, the column names and types for an explicit schema must be hard-coded at query time. Wouldn't it be great if we could do this?
DECLARE @Schema NVARCHAR(MAX);
SELECT @Schema = STRING_AGG(
QUOTENAME(k.[key]) + ' ' +
CASE
WHEN k.type = 0 THEN 'VARCHAR(MAX)'
WHEN k.type = 1 THEN 'VARCHAR(MAX)'
WHEN k.type = 2 THEN 'NUMERIC(38, 5)'
WHEN k.type = 3 THEN 'BIT'
WHEN k.type = 4 THEN 'VARCHAR(MAX)'
WHEN k.type = 5 THEN 'VARCHAR(MAX)'
ELSE 'VARCHAR(MAX)'
END,
', ')
FROM OPENJSON(@JsonData) j
CROSS APPLY OPENJSON(j.value) k
WHERE j.[key] = 0
SELECT *
FROM OPENJSON(@JsonData)
WITH (
SCHEMA = @Schema
)
What if we used an existing object definition for an explicit schema? Any of these options would be pretty sweet, too:
--Table definition for Explicit Schema
SELECT *
FROM OPENJSON(@JsonData)
WITH (
SCHEMA = OBJECT_DEFINITION(OBJECT_ID('dbo.MyTable'))
);
--View definition for Explicit Schema
SELECT *
FROM OPENJSON(@JsonData)
WITH (
SCHEMA = OBJECT_DEFINITION(OBJECT_ID('dbo.MyView'))
);
--User-Defined Table Tyype definition for Explicit Schema
SELECT *
FROM OPENJSON(@JsonData)
WITH (
SCHEMA = OBJECT_DEFINITION(OBJECT_ID('dbo.MyUserDefinedTableType'))
);
Outside of dynamic TSQL (which I love...but ick!) I've not found a way to query an unknown piece of JSON data in a manner that returns a tabular result set. We have a bridge from NoSQL to SQL Server, but it's a little shaky. We need some reinforcements.
Comments